
发布日期:2024-05-06 05:44 浏览次数:次
梯度下降算法(Gradient Descent Optimization)是神经网络模型训练最常用的优化算法:
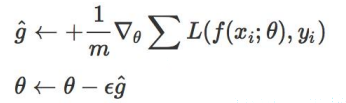
缺点:
Momentum是模拟物理里动量的概念,即,前几次的梯度也会参与到运算中,因此:
它可以有效的解决模型陷入鞍点的问题;
而且它在前后梯度方向一致时,能够加速学习;在前后方向不一致时,能够抑制震荡。
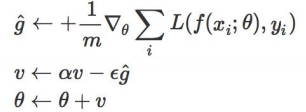
Nesterov Accelerated Gradient是动量梯度下降算法的改进版本,其速度更快。
其可以解释为往标准动量方法中添加了一个校正因子:
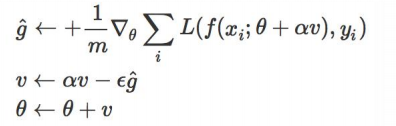
在训练模型时,我们会想对出现频率低的特征进行快一点的更新,而高频的进行慢一点的更新,而上述方法所有参数的学习率都是统一的,并不能满足我们的要求。因此,自适应学习率算法AdaGrad提出了

在训练迭代的过程中,其学习速率是逐渐衰减的,经常更新的参数其学习速率衰减更快,因此非常易于稀疏数据的训练。
缺点:在深度学习中,深度过深时或者某次迭代时梯度过大会使r的值变的非常大,会造成训练的提前结束。
RMSprop是对Adagrad算法的改进,其实思路很简单,引入一个衰减系数,让梯度平方的累计量r 每回合都衰减一定比例。该方法主要是解决训练提前结束的问题,适合处理非平稳目标,对RNN的效果特别好。

自适应矩估计(Adaptive moment estimation,Adam)本质上是带有动量项的RMSprop,其结合了Momentum和RMSprop算法的思想。它利用梯度的一阶矩估计 和 二阶矩估计 动态调整每个参数的学习率:

其中ρ1,ρ2的建议值分别为0.9和0.999。

左边: 在MNIST上训练多层神经网络
右边: 在CIFAR10上训练多层卷积网络
总结:
服务热线


