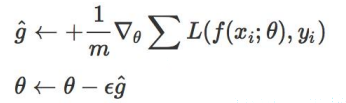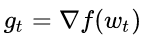模型每次反向传导都会给各个可学习参数p计算出一个偏导数,用于更新对应的参数p。通常偏导数不会直接作用到对应的可学习参数p上,而是通过优化器做一下处理,得到一个新的值,处理过程用函数F表示(不同的优化器对应的F的内容不同),即,然后和学习率lr一起用于更新可学习参数p,即。假设损失函数是,即我们的目标...
梯度下降算法(GradientDescentOptimization)是神经网络模型训练最常用的优化算法:缺点:选择合适的learningrate比较困难:如果数据是稀疏的,我们会想对出现频率低的特征进行快一点的更新,而高频的进行慢一点的更新,这时候SGD就不太能满足要求了SGD容易收敛到局部最优,...
目录?梯度下降方法:SGD,Momentum,AdaGrad,RMSProp,Adam概述批量梯度下降法(Batchgradientdescent)随机梯度下降法(Stochasticgradientdescent)小批量梯度下降在线学习映射化简和数据并行冲量梯度下降,Momentum:其他三种经典...
深度学习的优化目标都是最小化目标函数,方式为bp算法,深度学习框架如tensorflow,pytorch一般通过封装的优化器实现这一过程,本文详细总结了现有的优化器。目录:[toc]待优化参数:$heta$,目标函数:$f(heta)$,学习率:$\eta$第t个时刻参数的梯度:$g_t=\bigt...
上一篇:CUDA编程入门之优化器GD上一篇主要介绍了经典的梯度下降法算法并阐述了其存在的一些局限,例如,在训练过程中,当接近最优值时梯度会比较小,由于学习率固定,普通的梯度下降法的收敛速度会变慢,有时甚至陷入局部最...
前面我们介绍了如何搭建网络模型,在模型搭建好之后一个非常重要的步骤就是对模型当中的权值进行初始化。正确的权值初始化可以加快模型的收敛,而不恰当的权值初始化可能会引发梯度的消失或爆炸,最终导致模型无法训练。梯度消失与爆炸Xavier方法与Kaiming方法常用初始化方法梯度消失与爆炸首先观察模型是怎么...
优化器就是在梯度下降过程中指引各个参数向着最优点前进的控制器,在优化的过程中,其会不断调节下降的大小,直到最优点。在梯度下降过程中我们最关键的是便是确定优化的方向(梯度)和前进多长的步子。方向主要是确定优化的方向,一般通过求导便可以求得,步子就是决定当前走多大,因...
当我们使用机器学习的时候,最开始都是初始化一组参数,然后不断优化迭代,得到最终的结果。所以优化算法也是机器学习中很重要的一个组成部分。我们之前提到过的梯度下降法,牛顿法这些便是很经典的优化方法。SGD首先是s...
服务热线
截屏,微信识别二维码
微信号:wixin888
(点击微信号复制,添加好友)
打开微信