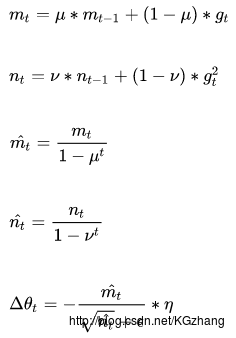参考文献:Hyperband:Bandit-BasedConfigurationEvaluationforHyperparameterOptimization机器学习中模型性能的好坏往往与超参数(如batchsize,filtersize等)有密切的关系。最开始为了找到一个好的超参数,通常都是靠人工...
torch.optim是一个实现了多种优化算法的包,大多数通用的方法都已支持,提供了丰富的接口调用,未来更多精炼的优化算法也将整合进来。为了使用torch.optim,需先构造一个优化器对象Optimizer...
牛顿法是一种用于求解无约束优化问题的迭代方法,它利用函数的一阶和二阶导数信息来寻找函数的极值点。在Python中,可以使用SciPy库中的`optimize.minimize`函数来实现牛顿法。下面是一个使用牛顿法求解无约束优化问题的...
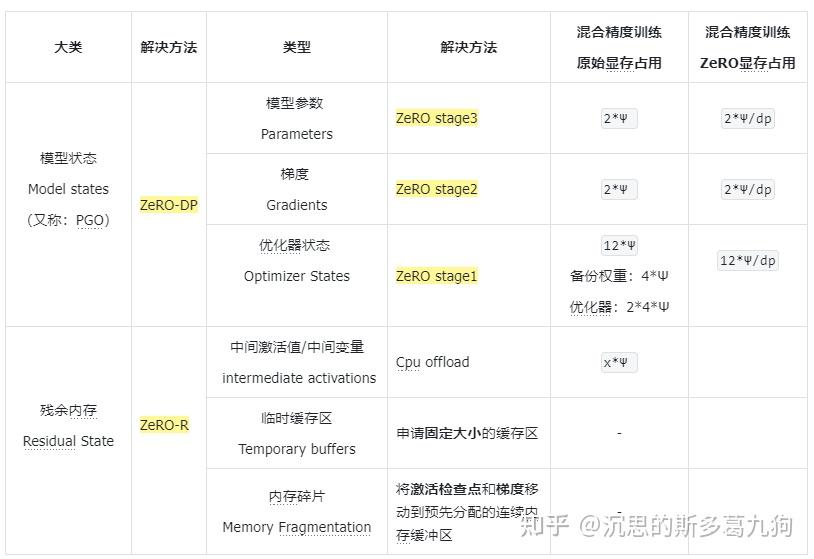
分布式训练topic由以下几部分组成:LLM训练01分布式通信LLM训练02显存占用分析LLM训练03高效训练方法LLM训练04数据并行LLM训练05ZeRO系列LLM训练06流水线并行LLM训练07张量并行LLM训练08Megatron-LM源码分析微软一共发布了4篇论文:ZeRO:Memoryo...
所谓深度神经网络的优化算法,即用来更新神经网络参数,并使损失函数最小化的算法。优化算法对于深度学习非常重要,如果说网络参数初始化(模型迭代的初始点)能够决定模型是否收敛,那优化算法的性能则直接影响模型的训练效率。了解不同优化算法的原理及其超参数的作用将使我们更有效的调整优化器的超参数,从而提高模型的...
这一部分其实两年前就进行过学习,现在把这一部分从笔记本上总结记录下来,主要来源还是那个有关优化算法的综述论文[1]。利用梯度(也就是网络参数的一阶导)来对参数进行优化是一种直接的思想,但是单纯利用当前梯度对参数进行优化容易遇见参数解停留在局部最佳...
本文是从网上的资料加上自己的总结而来的,要感谢PyTorch学习笔记(七):PyTorch的十个优化器:Pytorch中常用的四种优化器SGD、Momentum、RMSProp、Adam:机器学习:各种优化器Op...
网络优化(1)网络优化(2)在上两节中,我们介绍了网络优化的一些相关内容;在实际深层神经网络中,我们常常会陷入局部最优以及鞍点之中,为此我们可以调整批量、步长和学习率使我们优化更快更好的收敛。同时为了防...
服务热线
截屏,微信识别二维码
微信号:wixin888
(点击微信号复制,添加好友)
打开微信